ChatGPT(有料版)に、新しいサービス「GPT Builder」が追加されました。
何かの目的に特化してカスタマイズしたChatGPTを作ることができます。
このサービスでは、カスタマイズしたChatGPTを作る際に、特定のドキュメントを「知識」として与えることができます。
これがあれば、先週試したLlamaIndexは要らないかもしれません。
というわけで早速試してみました。
使うドキュメントは前回同様、今年度の情報通信白書です。
(私は総務省の回し者ではありません。単にChatGPTにインデックスされていない情報で、著作権上の問題が無いものが良いと思ってこれを選んでいます。)
GPT Builderを起動すると、親切にガイドしてくれるので、基本的にChatGPTに話すのと同じ感じで進められます。


どんなものを作るか指定すると、プロフィール画像を生成してくれます。
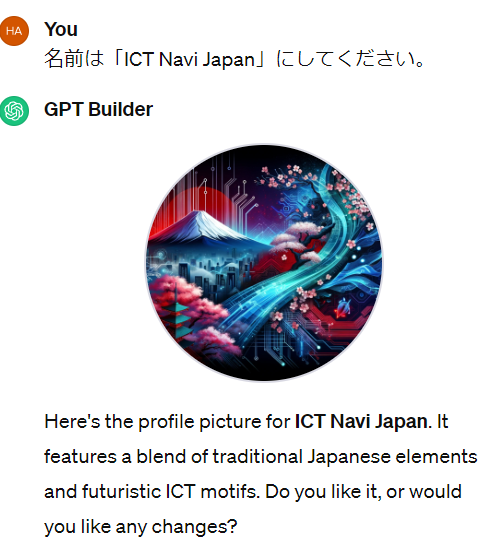
もちろん、プロフィール画像は自分で指示して作らせることもできます。
たいていは、自分で指示する方が良いです。


プロフィール画像を作成した後は、このボットのコミュニケーションスタイルを指定できます。


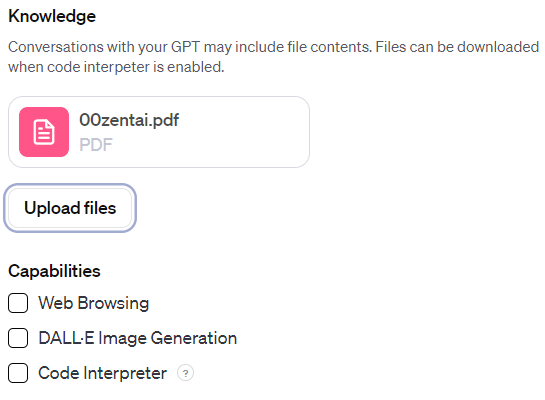
次に、Configureを選択すると追加の設定を行えます。ここは対話形式ではありません。
今回は情報通信白書を知識として与えます。
令和5年度の情報通信白書のPDF版とHTML版がありますが、PDFの「全体版」をアップロードします。
実はHTML版の方がChatGPTに解析しやすいのではないかと思って、情報通信白書のHTML版をスクレイピングしてGPT Builderにアップロードしてみたのですが、「文章を抽出できなかった」としてエラーになってしまいました。
なお注意点として、アップロードしたファイルは
(1)その内容がChatGPTとの会話の中に含まれる可能性がある
(2)コードインタープリタをONにした場合はダウンロードされる可能性がある
ということです。
では、質問をしてみます。前回の記事と同じことを尋ねてみましょう。




前回の回答よりも情報量は多いように思います。与えたファイルの処理の仕方が違うのかもしれません。
というわけで、文書の内容に関する質問に答えるだけなら、わざわざLlamaIndexを使わなくても、簡単にボットを作ることができそうです。
ファイルそのものを公開したくない場合や、複数のファイルに情報が分散している場合などに役に立ちそうです。
やり取りの進展に従ってもう少し複雑な処理を行いたい場合や、与える知識そのものを頻繁に更新する場合などは、LangChainを使ったりすることになると思います。一方、GPT Builder単体でも、ファイルをアップロードする以外に、今回は試してみませんがAPI経由で、他サイトのデータを知識として取得したり、いろいろ追加のアクションを行わせることもできるようです。

一方LlamaIndexは、単純な文書についての質問回答というより、ユーザの入力してきた質問をいかに拡張するか、という方向に発展していくようです。


コメント