来月号のInterfaceには、MicroPythonの高速化の記事が出るそうです。
【フライング】2019年5月号(3/25発売)の目次はこんな感じです.
★特集「あなたの知らないモダンOSの世界」
・IoT時代モダンOSの研究
・マイコンで欠かせないMicroPython高速化の研究
・今どきモダンIoT実験室★特設「保存版 OS事典」https://t.co/DbkzsJnfbE pic.twitter.com/kqo0cntMgu
— コンピュータ技術実験月刊誌「Interface」 (@If_CQ) 2019年3月18日
記事と関連するかは分かりませんが、以前見たDamienの講演をこれで思い出したので貼っておきます。
PyCon AU 2018 | Writing fast and efficient MicroPython
30分ほどのビデオで、Lチカとファイル読み込みをいろいろなテクニックを使って高速化していくというものです。
最初のスクリプトはこんな感じで、50KHzくらいで点滅しますが、最終的にはこれが500倍高速になります。
led = machine.Pin('LED_BLUE')
fori in range(n):
led.on()
led.off()
用いられているテクニックを列挙すると
・素のまま → 56.93 KHz
・関数にする → 66.36 KHz
・メソッド呼び出しを省略 → 182.39 KHz
・ループを展開(8個) → 222.16 KHz
・ネイティブコード化 → 287.73 KHz
・Viperコード+レジスタ直叩き → 12890.68 KHz
・インラインアセンブラ → 27359.25 KHz
となっています。
基本的には、ヒープからメモリを取らない=グローバル変数ではなくローカル変数を使う、メモリ確保はループに入る前に行う、言語エンジンが行う処理をできるだけキャッシュしておく、といったことが有効です。
コードを関数化すると、関数内の変数がグローバルではなくなるので、それだけでも効果があります。
メソッドの呼び出しを省略(キャッシュ)するのは簡単で効果もかなり高いですね。
また、ファイル読み込みの高速化も解説されており、
・read()の代わりにreadinto()を使う
という手法が紹介されています。
後者は呼び出し側で用意したバッファにデータを上書きする関数で、これによってヒープにメモリを確保するというコストの高い処理が省略できます。
この講演ビデオが興味深いのは、高速化テクニックの他に、図表類がいろいろ出てくるところです。(初出というわけではなく、Damienの講演にはよく出てきます)
引用ばかりになりますが、ポイントを拾ってみます。
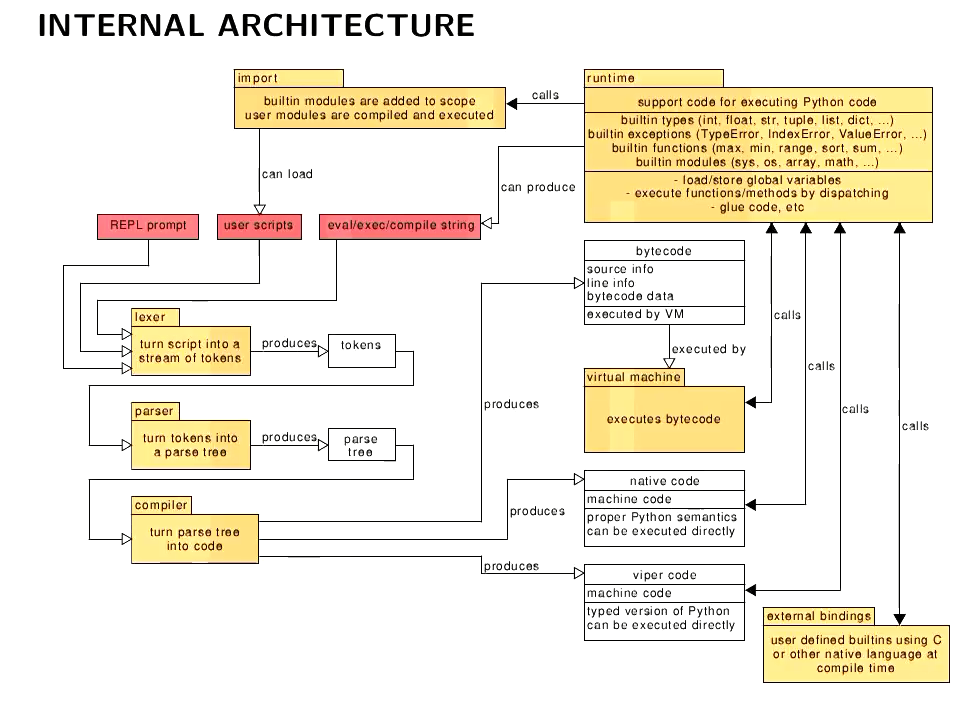
まずはMicroPythonの全体アーキテクチャ。
通常、スクリプトはバイトコードにコンパイルされてVMで実行されますが、それ以外にネイティブ(インラインアセンブラ)とviperという直接実行できるコードも使えることがわかります。

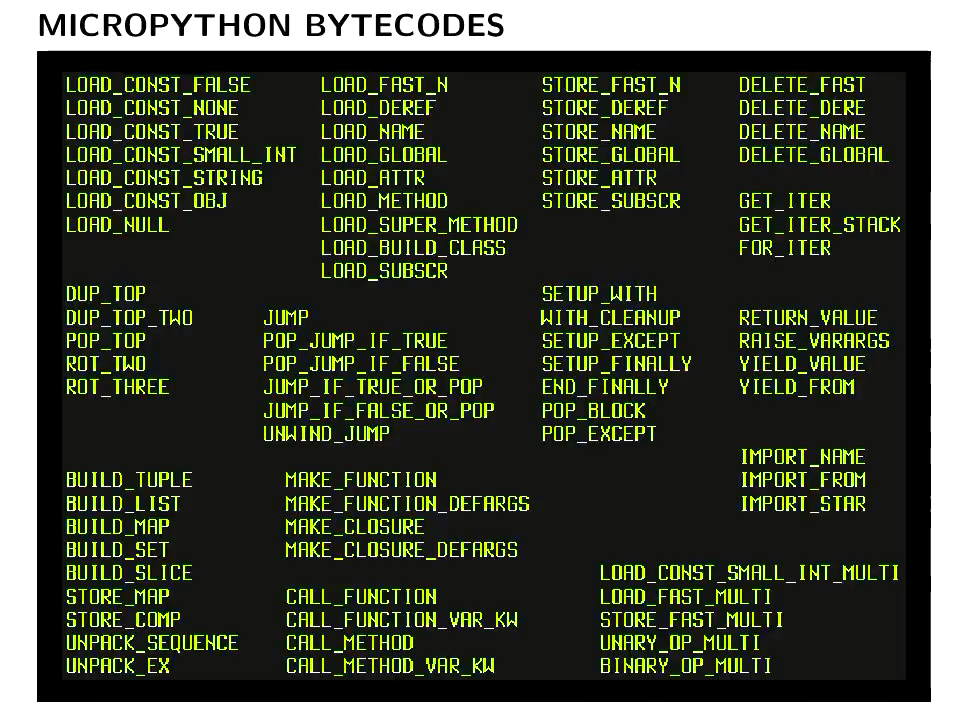
VMのバイトコード一覧と、スクリプトをバイトコードコンパイルした例もありました。
ちなみにバイトコードの仕様はときどき更新されています。

コメント