
今回は、PicoのRAMに白黒のVGA解像度のフレームバッファを作成し、図形を描画してscanvideoライブラリで表示させてみました。
白黒であれば、VGAサイズで必要なメモリは38400バイトですので、PicoのRAMに問題なく納まります。
作成したのは、直線の描画と、画面をノイズで塗りつぶすという2つのデモです。USB経由でターミナルにつながり、スペースの入力でデモを切り替えます。以下は動作中の画面です。(アナログ放送と共に消滅した、懐かしい「砂嵐」が見られます。)
これまでも、scanvideoを使ってVGA信号を生成させるデモをいくつか作ってきましたが、今回は以前のものとは異なる特徴があります。
これまで作ってきたデモはどれも、画面の更新はVGA信号の垂直ブランキング期間に完了させていました。しかし今回は、垂直ブランキング期間内に画面の更新が完了しないような処理を扱います。
実際、画面をノイズで埋めるにはフレームバッファ全体に乱数を書き込みますが、この処理を垂直ブランキング期間に行おうとすると、下の写真のように時間切れになって表示できません。(スキャンラインバッファの生成が間に合わないと、左半分がブルー、右半分が黒の信号が生成されます。)

そこで今回のプログラムでは、フレームバッファの更新とVGA信号の生成という2つの処理を独立させます。それには、描画とVGA信号生成の2つのタスクを、RP2040のデュアルコアに1つずつ割り振ることもできますし、2つのタスクをシングルコアで時分割で処理することもできます。
今回は両方を試してみました。
コードは以下にアップロードしてあります。

以降では、以下の4つのトピックを説明していきます。
scanvideoを使ったフレームバッファのVGA信号生成
この処理は、基本的には以前作成した静止画の表示処理と同じです。
今回のフレームバッファでは、1ピクセルを1ビットで表現しています。1バイトの中では、LSB側のビットがより左側へ来ることにしました。BUF_ROW_WORDSは640/32 = 20です。
#define BUF_ROW_WORDS 20
#define BUF_LINES 480
uint32_t framebuffer[BUF_ROW_WORDS * BUF_LINES];スキャンラインバッファでは1ピクセルは16ビットですので、フレームバッファのビットを参照して、ピクセルのオンとオフに対応する16ビットの色データをスキャンラインバッファへ埋めていきます。
ここで、シンプルに1ピクセルずつ処理していくと、処理が間に合わなくなりました。スキャンラインバッファに16ビットずつ640回書き込む処理が重すぎるようです。そこで以下のコードのように、32ビット(2ピクセル分)ずつ書き込むようにしています。
uint32_t twopixels[4];
void set_color_table(uint32_t fg_color, uint32_t bg_color) {
twopixels[0] = bg_color;
twopixels[1] = bg_color << 16 | fg_color;
twopixels[2] = fg_color << 16 | bg_color;
twopixels[3] = fg_color << 16 | fg_color;
}
int32_t inline __time_critical_func(single_scanline)(uint32_t *buf, size_t buf_length, uint32_t *data) {
uint32_t *p = buf + 1;
for(int i = 0; i < BUF_ROW_WORDS; i++) {
uint32_t w = *(data + i);
for(int b = 0; b < 16; b++) {
*p++ = twopixels[(w >> (b+b)) & 3];
}
}2つのピクセルが並ぶパターンは「00」「01」「10」「11」の4通りですから、その4通りについてスキャンラインバッファに書き込む32ビット分のデータをあらかじめ用意しておいて、フレームバッファの2ビット分の状態に応じて、その中から1つを選んで使用しています。これで、32ピクセル分のデータを16回の書き込みでスキャンラインバッファへ書き込んでいます。
フレームバッファへの点と直線の描画
上のscanvideoの処理によって、フレームバッファにデータを書き込めば、それが画面表示に反映されるようになりました。
そこで、まず座標x,yのピクセルを反転させる関数set_pixel_xor(int x, int y) を作成しました。
void set_pixel_xor(int x, int y) {
framebuffer[x / 32 + y * BUF_ROW_WORDS] ^= (1 << (x % 32));
}次に、これを使って直線を描画する関数line(int x0, int y0, int x1, int y1)を作りました。これはブレゼンハムのアルゴリズムという有名なアルゴリズムを使っています。詳細はリンク先を参照してください。
なお今回のプログラムでは、フレームバッファに関しては上記の他に
・フレームバッファ全体に0を書き込む(画面クリア)
・フレームバッファ全体に乱数を書き込む(画面をノイズで埋める)
という2つの処理も実装しています。
デュアルコアでの並列処理
上で述べたように「フレームバッファからのVGA信号生成」と「フレームバッファへの図形描画」の2つの処理を並列して行う必要があります。
下図のようにそれぞれの処理をRP2040の2つのコアに割り当てるのは、そのシンプルな方法と言えるでしょう。
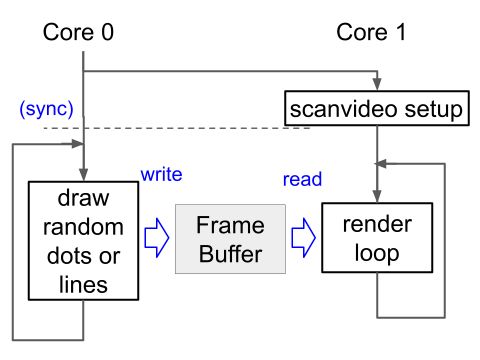
Pico SDKでデュアルコアを使用する方法は以下のようになります。
#include "pico/multicore.h"
void core1_main() {
}
void core0_main() {
}
int main(void) {
multicore_launch_core1(core1_main);
core0_main();
return 0;
}簡単ですね。
Core 0の処理は、Core 1とは全く関係なくフルスピードで実行されますが、以前のデモと同様に垂直ブランキング期間に合わせて処理を行うこともできます。
そのための関数はscanvideo_wait_for_vblank()で、その名前の通り垂直ブランキング期間が始まるまで処理をブロックします。今回作成したデモでは、直線の描画を行う前にこの関数を呼んでいます。従って、1フレームごとに直線を1本だけ描画することになります。
Core 0とCore 1の処理を排他制御したい場合には、ミューテックスやセマフォがSDKに用意されています(C/C++ SDKマニュアルの4.2.6節と4.2.7節)。また、これをscanvideoで使うサンプルがpico-playgroundの中のscanvideo_minimalにあります。
ミューテックスやセマフォは、公衆トイレの「鍵」みたいなものを想像してください。トイレの中に人が入っていると、鍵が「赤」になっていて、他の人は入ることができません。トイレから出ると、鍵は「青」になるので、次の人が入ることができます。ミューテックスは定員が1のトイレを実現することができます。セマフォでは、定員が1より大きいトイレも実現することができます。
次のコードでは、以下の3つのセマフォAPIを使います。
・sem_init(semaphore_t *sem, int16_t initial_permits, int16_t max_permits)
セマフォを初期化します。第一引数はセマフォに使う変数、第二引数は、現在トイレにあと何人はいれるか、第三引数はトイレに「最大」何人入れるかを表します。
・sem_release(semaphore_t *sem)
トイレから1人出ます。
・sem_acquire_blocking(semaphore_t *sem)
トイレに空きがあれば入り、空きがなければ空きができるまでブロック(停止)します。
上の図で、「(sync)」と書いてある部分がありますが、これはscanvideoの初期化が終わる前にCore 0の処理が始まらないように、Core 1側の処理と同期することを表しています。以下のようにセマフォを使うと、この同期処理を行うことができます。
#include "pico/multicore.h"
static semaphore_t video_initted;
void core1_main() {
scanvideo_setup(&VGA_MODE);
scanvideo_timing_enable(true);
sem_release(&video_initted);
render_loop();
}
void core0_main() {
}
int main(void) {
sem_init(&video_initted, 0, 1);
multicore_launch_core1(core1_main);
sem_acquire_blocking(&video_initted);
core0_main();
return 0;
}このコードでは、Core 1側がsem_release()を実行するまで、Core 0側はsem_acquire_blocking()でブロックされます。(もっとも、今回のデモではscanvideoの初期化が終わる前にフレームバッファを書き換えても、何も問題は起こりませんが。)
タイマ割込を使ったシングルコアでの並列処理
二つのコアを使う代わりに、一つのコアで「VGA信号生成」と「フレームバッファへの描画」を行うことも可能です。このような処理の例は、pico-playgroundの中のmandelbrotデモにあります。
この場合は、下図のようにVGA信号生成のタスクを割り込みによって呼び出します。
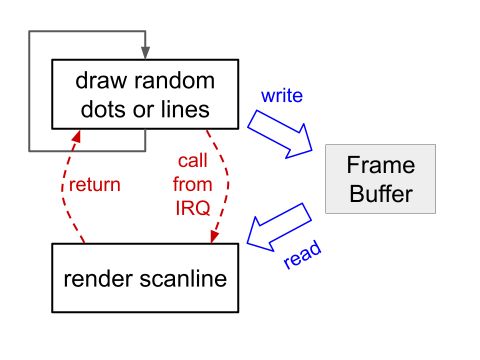
割り込みはスキャンラインバッファへの書き込みが必要になった時点で行われるのが望ましいのですが、mandelbrotデモを見る限り、タイマで割り込みをかけて、新しいスキャンラインバッファが処理可能かどうかポーリングする必要があるようです。(タイマ割り込みの解説はC/C++ SDKマニュアルの4.2.11節にあります。)
具体的には、タイマの割り込みハンドラは以下のようになっています。
#define TIMER_PERIOD 200
int64_t timer_callback(alarm_id_t alarm_id, void *user_data) {
struct scanvideo_scanline_buffer *buffer = scanvideo_begin_scanline_generation(false);
while (buffer) {
render_scanline(buffer);
scanvideo_end_scanline_generation(buffer);
buffer = scanvideo_begin_scanline_generation(false);
}
return TIMER_PERIOD;
}このコードでは、scanvideo_begin_scanline_generation()の引数がfalseになっています。引数がtrueの場合には、スキャンラインバッファが用意されるまで呼び出し側はブロックされますが、引数がfalseの場合はブロックされず、その代わりscanvideo_begin_scanline_generation()の戻り値がNULLかどうかで、スキャンラインバッファが用意できたかどうかを判定できます。
従って、この割り込みハンドラが呼び出され、スキャンラインバッファが用意できていれば、whileの中身が実行されますが、用意できていない場合は何も実行されずにハンドラは終了します。戻り値のTIMER_PERIODは、次回この割り込みハンドラが再度呼び出されるまでの時間で、今回のコードでは200μsecになっています。
ちなみにmandelbrotデモではTIMER_PERIODは100μsecに設定されていました。今回はカット&トライで200μsecにしています。値を大きくしすぎると、スキャンラインバッファの用意が間に合わなくなります。VGA信号では、1画面が525スキャンライン分であり、それが毎秒60フレームですから、スキャンラインは概ね1/30000秒(30μsec)に一回描くはずですが、それよりは長いポーリング周期でも大丈夫なようです。
タイマ割り込みを登録するためのAPIは、
add_alarm_in_us (uint64_t us, alarm_callback_t callback, void *user_data, bool fire_if_past)
です。第一引数が次の割り込みまでの時間、第二引数が割り込みハンドラ、第三引数が割り込みハンドラに渡すデータ(任意)です。第四引数は、もしadd_alarm_in_usの実行中にタイマの時間が来た場合に、コールバック関数ををadd_alarm_in_usから直接呼び出すかどうかを指定します。
今回はmain()内で以下のように登録しています。
int main(void) {
add_alarm_in_us(TIMER_PERIOD, timer_callback, NULL, true);
render_loop();
return 0;
}このシングルコア版では、VGA信号の生成処理が優先されますので、フレームバッファへの描画処理は遅くなります。シングルコア版とデュアルコア版で砂嵐を見比べてみると、明らかにデュアルコア版のほうが砂嵐が綺麗です。シングルコア版では、砂嵐がちらついて見えます。


コメント