

前回の記事では、訓練済みのモデルを使って「Yes/No」を認識しましたが、他の単語を認識させるモデルを訓練するためのスクリプトも用意されていますので、試してみました。
スクリプトはこちらです。
tensorflow/train_speech_model.ipynb at master · tensorflow/tensorflow
ここから、Run in Google Colabを選択すると、クラウド上で学習をさせることができます。

Google ColaboratoryはJupyter Notebookのオンライン版と思えばよく、Web上のインタフェースでPythonスクリプトを実行できます。
もちろんローカルの端末にダウンロードして実行することもできますが、Colabを使ったほうが高速で楽です。
12時間経つとデータが自動消去されるという制約はありますが、自分のアカウントのGoogle Driveをマウントしてそちらへデータをコピーすることができます。(詳しくはぐぐって下さい)
認識させるキーワードはデフォルトでyes,noになっていますので、ここを書き換えます。用意されているキーワード群(キーワード設定の行の2行上に書かれています)の中から2つのキーワードを選択します。
このとき、up, downのようにスペースを入れないように気をつけてください。スペースがあるとエラーになるようです。
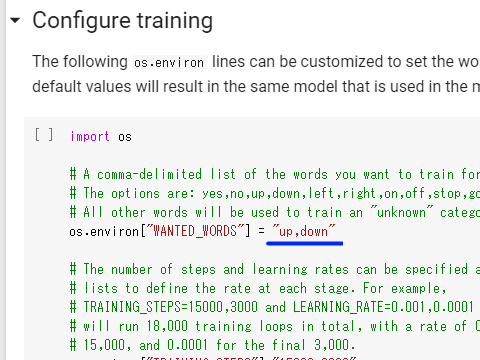
後は、セルを順番に実行していくだけです。Begin trainingのセルは、実行完了までに一時間半~二時間程度かかります。
最後に、Cのソースコードが出力されますので、これをコピーして保存しておきます。
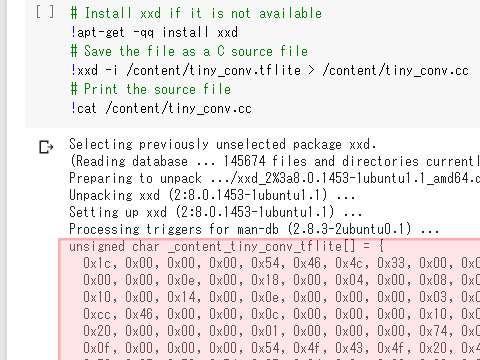
Web画面からコピーしてもいいですし、
from google.colab import drive
drive.mount('/content/drive')のようにしてGoogle Driveをマウントし、
!cp /content/tiny_conv.cc /content/drive/My\ Drive/として自分のGoogle Driveにコピーすることもできます。
作成したモデルのデータを使うには、まず先ほどコピーしたデータをsrc/micro_features/tiny_conv_micro_features_model_data.ccのデータと入れ替えます。
他に、キーワードの文字列が入っているsrc/micro_features/micro_model_settings.ccと、認識結果に基づいた処理を行うsrc/command_responder.ccも書き換えが必要です。
M5Stick-Cで「right, left」を認識させるためのコードを以下に置いておきます。
boochow/TFLite_Micro_MicroSpeech_M5Stack at m5stickc_left_right
認識結果はM5StickCのLCDに出力されます。


コメント