
 前回のジェスチャ認識デモに続いて、音声認識デモもM5Stackに移植してみました。
前回のジェスチャ認識デモに続いて、音声認識デモもM5Stackに移植してみました。
できること自体は以前試したSTM32F7 Discovery版と同じで、2つのキーワードに反応するキーワードスポッティングです。
音声入力にはM5Stack Fireに内蔵されているアナログマイクを使います。
このマイクは正直言って音質が良くないので、実験した限りではSTM32F7 Discoveryに比べると認識精度はかなり落ちます。
「No」は割と認識してくれるのですが、「Yes」は結構ハードルが高いです。
しかし、ともかく動作はします。
コード一式は以下のリポジトリに置いてあります。
boochow/TFLite_Micro_MicroSpeech_M5Stack
音声認識のモデル
このデモの音声認識モデルの詳しい解説は以下のページにあります。
tensorflow/tensorflow/lite/micro/examples/micro_speech at master · tensorflow/tensorflow
最後のほうにデータの流れを解説した図が載っていますが、入力は16KHzサンプリングの16bit符号付PCMデータです。
ここから30msec分の音声をFFTにかけたものを、時系列に並べていきます。
時間間隔は20msecです。(先頭10msecと、直前のデータの最後の10msecは同じ音声データということになります)
FFTの結果は43個の周波数帯に分離され、各周波数帯の係数は8bitで表現されます。
時間軸方向にこれを49回繰り返します。
これらを並べると縦43×横49の音声スペクトル分布画像ができます。ここからキーワードが持つ特有の周波数分布(の時間変化)を検出させます。
スペクトル画像の例(spectrogram.png )が下記のページに掲載されています。
docs/audio_recognition.md at master · tensorflow/docs
また、新しくモデルを訓練するためのスクリプトは下記で公開されています。
任意の単語で訓練できるわけではなく、あらかじめ用意された単語群(yes,no,up,down,left,right,on,off,stop,go)の中から単語を2つ選ぶようです。
tensorflow/train_speech_model.ipynb at master · tensorflow/tensorflow
移植ですが、今回もAdafruitの移植記事を参考にしながら進めました。
Overview | TensorFlow Lite for EdgeBadge Quickstart | Adafruit Learning System
Overview | TensorFlow Lite for Circuit Playground Bluefruit Quickstart | Adafruit Learning System
また、M5Stackの音声入力については、主に以下を参考にしました。
arduino-esp32/libraries/ESP32/examples/I2S/HiFreq_ADC at master · espressif/arduino-esp32
M5Stack_MicroPython/machine_i2s.c at master · m5stack/M5Stack_MicroPython
POC voice recorder for M5Stack Fire. For ESP32 Arduino Core.
コードの準備
ローカルにクローンしたリポジトリからESP32用のコードを生成するまでは、前回と同じ作業です。
今回もmainブランチを使っています。
以下のように、makeでソースコード一式を生成し、M5StackのzipファイルにしてM5Stack開発環境へ持ってきます。
$ make -f tensorflow/lite/micro/tools/make/Makefile TARGET=esp generate_micro_speech_esp_project
$ cd tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32/prj/micro_speech/esp-idf/
$ ls -CF
CMakeLists.txt LICENSE README_ESP.md components/ main/
$ zip -r esp32microspeech.zip components mainM5Stackの開発環境はWindows7+VS Code上のPlatformIOです。
前回同様、zipファイルにまとめたコードを展開し、「components/tfmicro」フォルダを「lib」配下へ、「main」フォルダの中身を「src」配下へ移動します。
そして、「main.cpp」、TensorFlow側の「main.cc」「main_functions.h」は削除し、main_functions.ccをmain.cppへリネームします。リネームしたmain.cppの中の#include “main_functions.h”は削除します。
ファイル構成は以下のようになります。
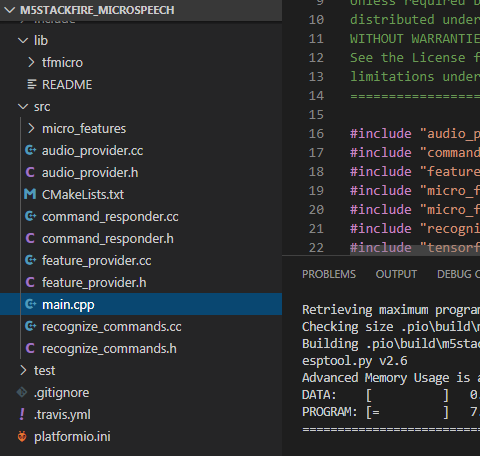
「platformio.ini」を編集して、以下のように設定を追加します。
前回よりもインクルードパスが増えていますので注意してください。
次に、ビルド時に出るエラーへの対処です。
recognize_commands.h
インクルードファイルが見つからないというエラーになりますが、
#include "tensorflow/lite/micro/examples/micro_speech/micro_features/micro_model_settings.h"
を
#include "micro_features/micro_model_settings.h"
に修正します。
tfmicro/tensorflow/lite/experimental/microfrontend/lib/fft.cc
以下のインクルードがエラーになります。
#include "kiss_fft.h" #include "tools/kiss_fftr.h"
platformio.iniに
-Ilib/tfmicro/third_party/kissfft
を追加すればOKです。(前掲のplatformio.iniには既にこの設定が追加してあります。)
tfmicro/tensorflow/lite/kernels/internal/reference/concatenation.h
前回と同じく、std::round()をround()に変更します。
tfmicro/third_party/kissfft/kiss_fft.h および tfmicro/tensorflow/lite/micro/tools/make/downloads/kissfft/kiss_fft.h
int16_tが未定義、というエラーが出ます。
同じインクルードファイルが2箇所にあるのはおかしい気がしますが、とりあえず両方のファイルに
#include <stdint.h>
を追加します。
これでライブラリ自体はビルドできるようになったはずです。
M5Stack Fireへの移植
M5Stack用の入出力のコードを追加していきます。
audio_provider.ccが音声入力処理、command_responder.ccが認識結果に対応する動作を記述するファイルです。
初期状態では、前者はダミーコード、後者は結果をテキストでシリアルポートへ出力するコードになっています。
音声入力はM5Stack Fireの内蔵マイク、出力はM5Stackで人気のM5Stack-Avatarライブラリを使うことにしました。
PlatformIOのライブラリ管理画面からM5Stack-Avatarライブラリをインストールしておきます。
audio_provider.cc
M5Stack Fireでは、アナログのMEMSマイクがADCに接続されています。
今回は音声を連続して内部のリングバッファへ取り込む必要がありますが、それにはいくつか方法があります。
まず、マイクの読み取りはタイマ割込みでサンプリング周期ごとにArduinoのanalogRead()関数で読み取る方法があります。これはArduinoでは標準的なやり方で、前掲のPOC voice recorder for M5Stack Fireでも使われています。(なお、このデモはpsRAMを録音領域に使うようになっているのですが、現在のESP32用Arduinoライブラリだとエラーになってしまいます。ps_malloc()を通常のmalloc()に直すと動作します。)
次に、ADCの値をI2Sで読み取る方法があります。これはESP32の機能で、ADCの値を内部的にI2Sの入力へ接続すると、CPUからはI2SインタフェースでADCを読み取ることができます。このやり方の便利なところは、タイマ割込みを使わなくてもI2SがDMAでバッファにデータを正確なタイミングで転送してくれる点です。
ただし、I2Sでは読み取ったデータが特殊な形式である点に注意が必要です。
ADCが12ビットなので、有効なデータは下位12ビットですが、データの値を0xFFFから引き算した結果が真の値です。
また、最上位3ビットにはADCのチャンネル番号が入っています。マイクの場合は、チャンネル6になります。
つまり、I2SでマイクのADC値を読み取ると、データは0x6FFF(最小値)~0x6000(最大値)の範囲で変動します。
このあたりのことは、前掲のHiFreq_ADCサンプルのコメントに書かれていました。
データの精度(読み取り値およびタイミング)はどちらのやり方でも違いはなかったのですが、今回はタイマ割込みは使わず、I2Sから値を連続で読み取りつつリングバッファへデータを転送する、というタスクをESP32の二つあるCPUコアの一方に割り当てる方法を採りました。
また、M5Stackのアナログマイクの音は結構ノイジーなのですが、それに加えて液晶バックライトのLEDのPWMからもノイズが載ってきます。この周波数帯がちょうどオーディオの帯域なので、今回はPWMをオフにしてバックライトは全点灯にしています。このノウハウも前掲のPOC voice recorder for M5Stack Fireから拝借しました。
ちょっと長いですがコードを載せておきます。(コメント文は削除しています。)
command_responder.cc
このファイルで提供されるAPIは
void RespondToCommand(tflite::ErrorReporter* error_reporter,
int32_t current_time, const char* found_command,
uint8_t score, bool is_new_command)だけです。found_commandに認識した文字列(「yes」「no」および「silence」「unknown」)が渡されるので、Avatarの表情と吹き出しに反映させます。
Avatarライブラリの初期化が必要なので、関数void InitResponder()を追加し、メインのsetup()から呼び出しています。
以下がコードです。
テスト
もともとマイクの感度が悪いので、かなりマイクの近くで発音しないと認識してくれません。
ちなみにマイクはボタンの近く、下図の位置にあります。

家族の冷たい視線を浴びながらテストしたのですが、マイクの感度の他に、M5Stackの内蔵スピーカーから常にノイズが出ているために、S/N比もかなり悪いです。
うまくいった場合のビデオを載せておきます。
感想
実はM5Stackのマイクの音質がかなり悪いことは最初から分かっていて、外部マイクにするかスピーカーをハードウェア的に改造しないといけないかと思っていました。
ですので、何とか認識してくれたことにちょっと驚いています。
移植については、TensorFlowそのものについては特に難しいことはなくて、今まで使ったことが無かったM5Stackのマイク入力周りの調査と実験に時間がかかりました。
逆に、こういった部分で苦労しなければ、それほど時間をかけずに移植できるのではないかと思います。

コメント